
CasJobs Guide
CasJobs
New features
The SciServer-enabled release of CasJobs includes these new features:
- A Single Sign-on Login Portal will log you in to all SciServer resources.
- A new MyScratch shared, temporary scratch space that allows you to run queries with very large result sets, and store those results for later analysis.
- Direct output to the new SciDrive cloud storage system makes the contents of your MyDB available as files through a Dropbox-like file system interface.
Brief instructions for using these new features are given below. Use these new features as they come up naturally in the course of your work. All other features of CasJobs should be unchanged.
As always, if you encounter problems or have questions or suggestions, please let us know using our feedback form.
Logging In
The first thing you may notice about CasJobs is that the login system has changed. The “create account” and “login” links have gone from the navigation menu, and have been replaced by the new SciServer login control in the top right corner of the window.

Click “Login” in the SciServer control to login to CasJobs via the SciServer Login Portal. Once logged in, you will automatically be redirected to the CasJobs Query page.
File Output
SciDrive is a new SciServer tool you can use to save your MyDB tables. In addition to downloading the contents of your MyDB tables in CSV, FITS, and VOTable formats, you can also save them to SciDrive.
The screenshot below shows how to select SciDrive from the Table Download menu. The textbox after SciDrive is the name of the container in SciDrive into which the table will be saved; the default value is first_container.
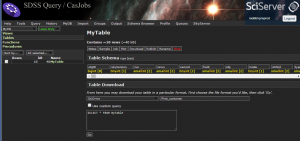
When you click Go, you will be taken to the Output page, where your request will be listed under “Pending Output”. Once the write to SciDrive finishes, the name of the table will appear under “Available Output”. The next time you log in to SciDrive, you will see the contents of that table in the container whose name you specified (defaulting into first_container). See the SciDrive instructions below to learn how to work with the data file you just wrote.
MyScratch
MyScratch provides support for very large queries.
The Sloan Digital Sky Survey contains so much data about the night sky that it is all too easy to write a scientifically useful query that fills up all the space in your MyDB. Although you can request additional space, it takes time for us to grant you the space, and it interrupts your work. This delay is particularly frustrating when you are selecting intermediate data that you know you will subset or summarize later, and so you know that the huge result set will only be temporary.
The new SciServer-based CasJobs system solves this problem by offering MyScratch shared temporary storage space. MyScratch is like a single very large database shared among all CasJobs users. Because MyScratch is shared among all users, older data are deleted when more space is needed for new user queries, but we guarantee that your data in MyScratch will be available for at least one week.
To select data into MyScratch, modify your query by adding an into clause. For example, to select into a table called MyTable in the MyScratch space, add into [myscratch:default].MyTable. Formatting is very important – the default myscratch call must be all lowercase, enclosed in brackets. The screenshot below shows an example of a query that selects SDSS DR12 photometric data into MyScratch.
![A query that selects data into default MyScratch by adding "into [myscratch:default]"](/wp-content/uploads/2015/12/myscratch_query-300x122.png)
Once you have selected data into a table in the MyScratch space, you can work with that table on your MyDB page just as you could any table in your own MyDB. The key is to select the [myscratch:default] context from the dropdown list at the top left of your MyDB page, just under the CasJobs logo. Once you choose the [myscratch:default] context, you can click on the Tables link to explore tables in MyScratch, just as you would in your own MyDB.
Once your query has completed, the output table you just created should appear in the tables listed for the [myscratch:default] context. Select the table you just created by clicking on its name in the tables listed in the MyScratch context. You will see the table contents displayed on the right hand side just like with MyDB tables. Note that there are fewer buttons for MyScratch table – you can add notes to the table, view a sample of the data or download it.
You can also query tables in MyScratch from the Query page, just as you can tables in your own MyDB. To query a table in MyScratch, you must do two things: select [myscratch:default] as the context from the Context menu above the query window, AND also add [myscratch:default] in front of the table name in your query, like this: from [myscratch.default].TableName.
If you want to download the MyScratch table, the procedure is the same as if you wanted to download a table from your own MyDB. Click on the Download button and select an output format. SciDrive is available as an option for tables in MyScratch as well.
If your table is large, the download operation could take several minutes or even hours. It might be more efficient to view and save subsets of your MyScratch table through the Query page.
Note that you have to be in the [myscratch:default] context to do anything with the MyScratch table, and even if you are in that context, you must always explicitly prefix the table name with the [myscratch:default]. qualifier.
More help
More help is available on CasJobs’s Help Page, which contains the following sections:
If you encounter bugs or have questions or suggestions, please let us know using our feedback form!